
As any college student can confirm, research papers are a colossal pain. When you start researching a topic, there’s one tool everyone turns to first: Google. But Google serves up links upon links of information that may or may not be relevant to what you’re looking for.
San Francisco-based startup Omnity wants to make it possible to both understand and visualize connections between documents and topics, whether or not they link to one another online. The company unveiled its semantic search engine at CES on Monday, and introduced a new way of searching publicly available data.
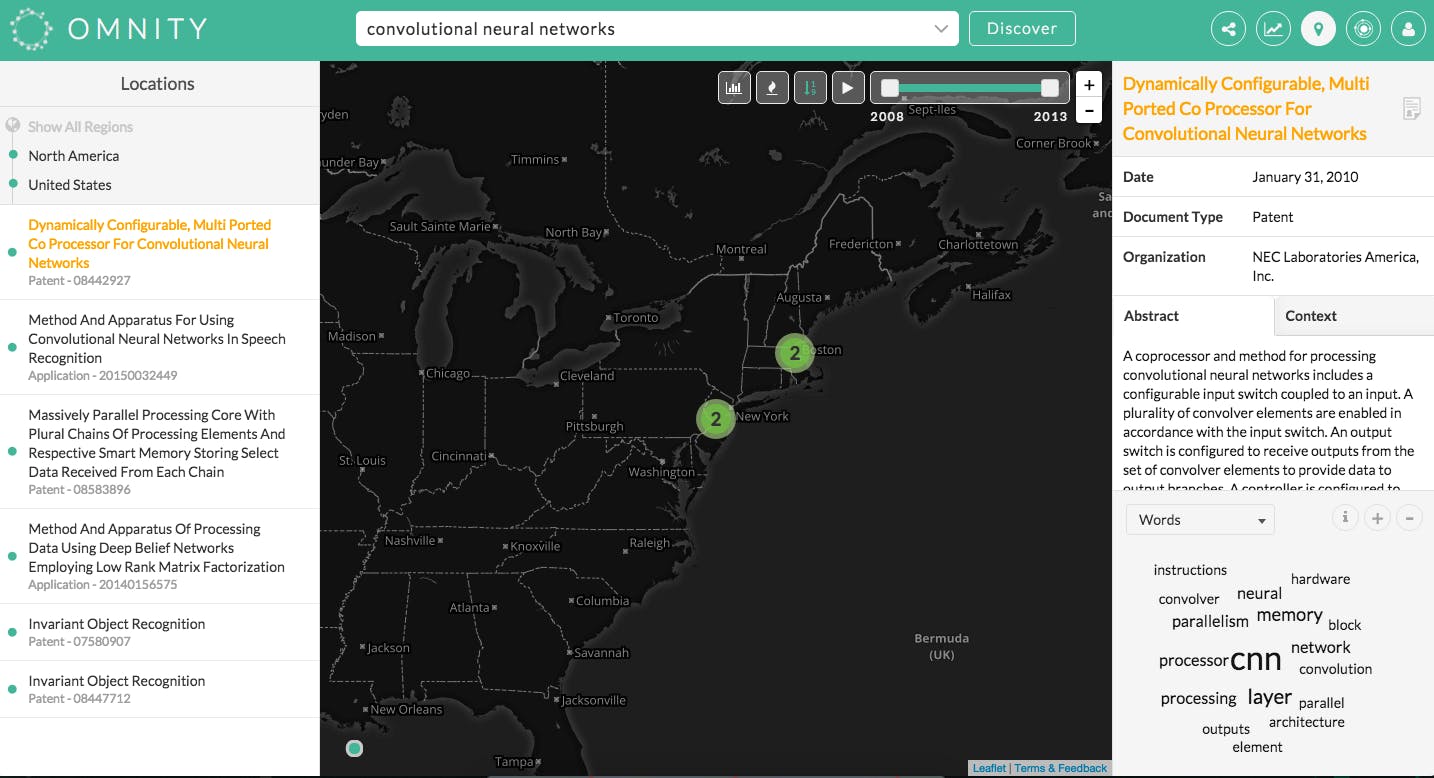
The platform searches meet ups, patents, Wikipedia, research papers, company websites, contact information and a slew of other data, and matches shared keywords to documents or topics your searching.
Unlike a traditional search system, which scours for keywords and headlines that seem to fit the words or phrase in the search bar, Omnity discovers related content that might not be linked, but draws connections between words or phrases that appear in content across the Web.
Omnity
As CEO and co-founder Brian Sager explained to the Daily Dot, the algorithm takes all the rare shared words and creates an equation that filters through documents and publicly available data. It avoids the need to have keyword-based search or a taxonomy system that ranks websites in a list based on keywords or SEO.
The more rare the word, the higher it counts towards the page relationship rank. The software omits common words that are found in a variety of documents or papers and only searches those that have multiple shared words in common. Omnity then surfaces relevant documents or websites and literally draws connections between data that’s related.
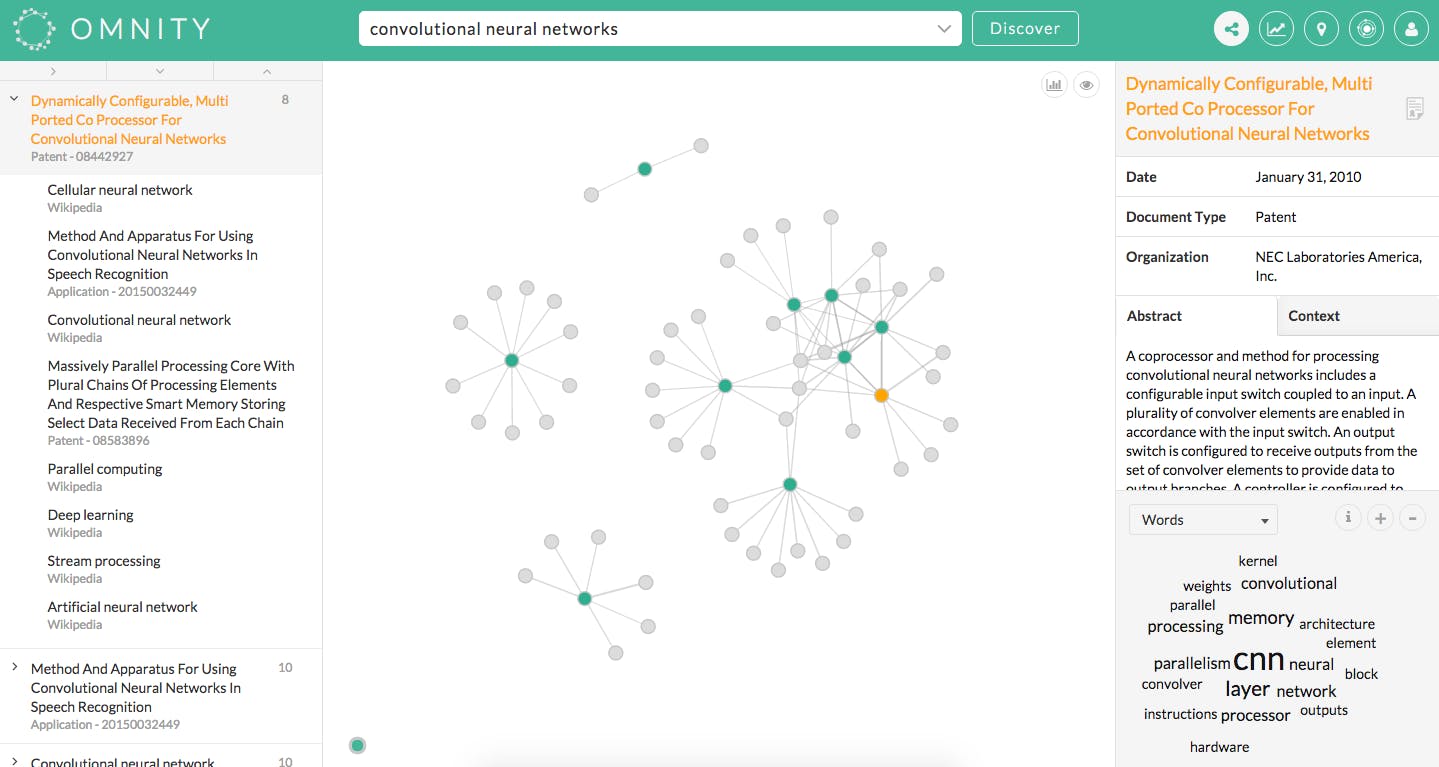
You’re given a list of results that include primary documents labeled in green that are directly related to the search terms, and secondary documents in grey that share vocabulary with the primary document they nest under. A visualization shows how they’re all connected.
The right-hand column includes a preview of your search result, where it came from, and a word cloud that shows the most popular words weighted by size according to their prevalence within the document. To see which documents contain a specific word, you can click on it to pare down your search results.
Omnity
It’s also possible to search entire documents—the tool will pull out keywords that appear more than others and use it as the basis for the search. For instance, Sager told me that when you input the text of a biography of Steve Jobs, Jobs’s patents are among the data that will appear in search results.
While most of the search results made sense with a handful of queries I tested, they weren’t all accurate. I tested the software on my story about coding programs in San Quentin State Prison, and it did show data regarding the prison and learn-to-code programs, but it also confused the last name “Houston” with the city in Texas and displayed information about programming meet ups in the area.
Omnity’s free tier searches public data, so you’ll see a lot of patents, Wikipedia pages, and group meet ups. A free student platform also searches open coursework and other research provided free to students and allows them to download three research reports per day. Paid tiers go deeper, and search for information that’s found behind paywalls like case law and scientific research papers with subscriptions that cost up to $400 per month and will be launching soon.
Sager and his team have worked on Omnity in stealth for four years, and finally launched publicly this week. The company is supported by grants from the National Science Foundation and has received an undisclosed amount of funding from private investors.
While education is an obvious market, Sager said enterprise uses could span across industries and include finance, medicine, law, and product development.
Photo via CollegeDegrees360/Flickr (CC BY-SA 2.0)

