
Even AI falls prey to sibling rivalries. The artificial intelligence Google used to defeat the world’s greatest (human) player in the ancient board game Go just got destroyed by its younger, smarter sibling.
Alphabet’s AI branch Google DeepMind unveiled AlphaGo Zero today, an improved artificial intelligence capable of achieving superhuman intelligence without any human input. Unlike the original AlphaGo, which learned by analyzing thousands of amateur and professional matches, AlphaGo Zero grows smarter by playing against itself.
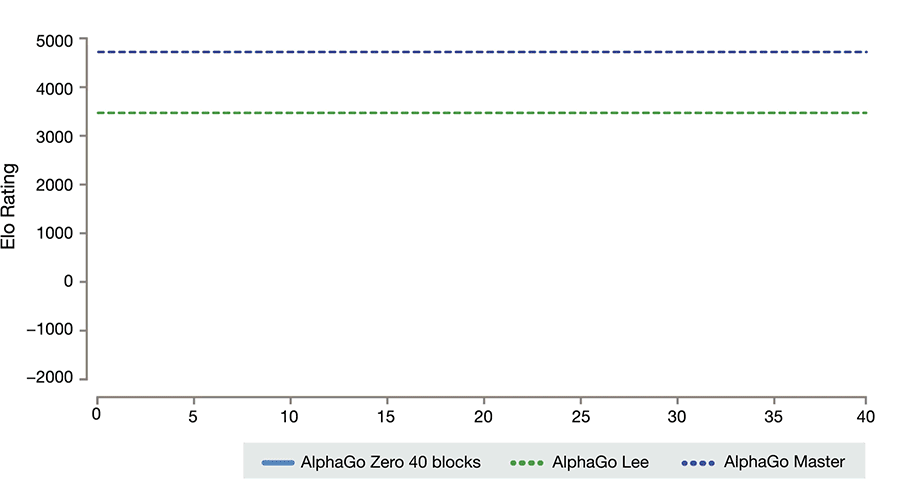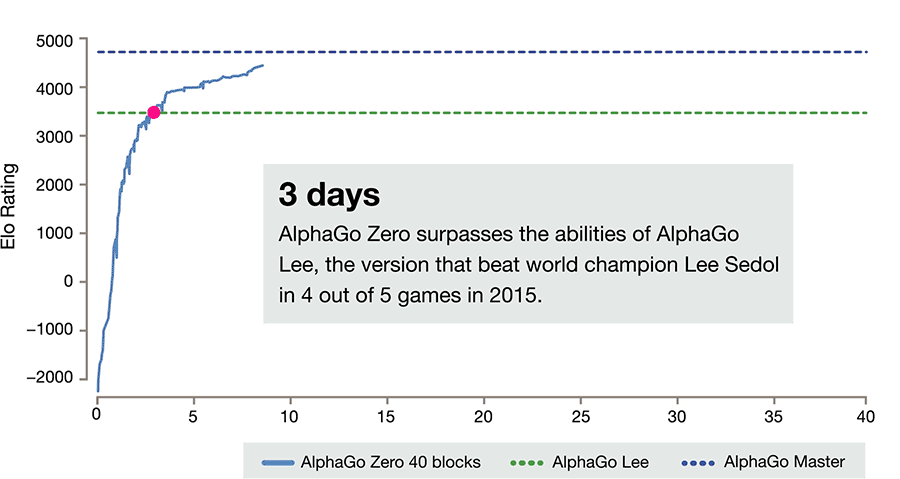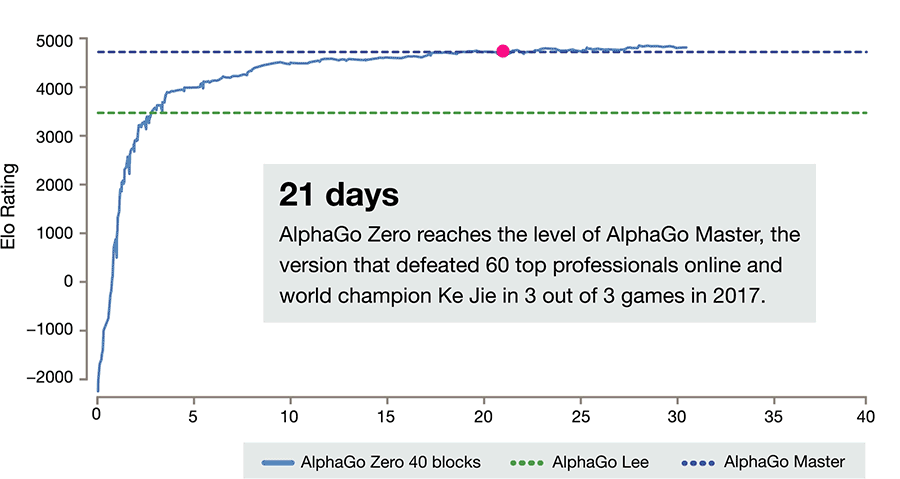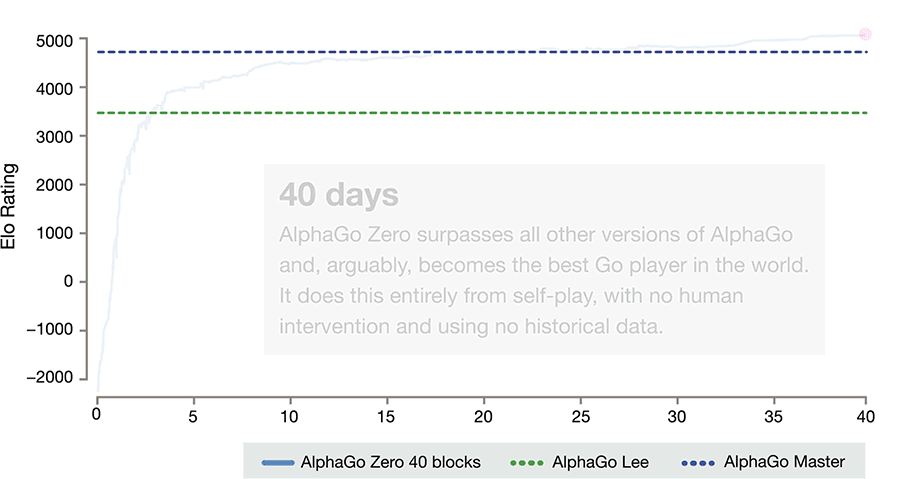
All it needed was a basic set of rules for the game. Using reinforced learning, the AI became its own teacher, rapidly playing and analyzing millions of games in a matter of days. Three days and 4.9 million games later, Zero defeated AlphaGo Lee, an early version of the AI that destroyed 18-time world master Lee Sedol in 2015. It won 100 games to 0. By day 21, it beat AlphaGo Master, a stronger version that earlier this year dominated Ke Jie, the world’s top Go player. By day 40, it had surpassed all previous versions, becoming the best Go player in the world.
The key to its rapid intelligence lies in the AI’s neural network, the digital equivalent of a brain, which lets it learn from observational data. Every time it plays a match, it fine-tunes its moves and predicts what will happen next. The improved network is then combined with a search algorithm to create a stronger version of itself. This happens over and over millions of times.
The groundbreaking method has several advantages. For one, Zero doesn’t rely on past human knowledge. That isn’t a problem with Go—a game that’s been played for 2,000 years—but it could be if there are limited sets of available data for a certain task.
“This technique is more powerful than previous versions of AlphaGo because it is no longer constrained by the limits of human knowledge,” AlphaGo wrote in a blog post. “Instead, it is able to learn tabula rasa from the strongest player in the world: AlphaGo itself.”
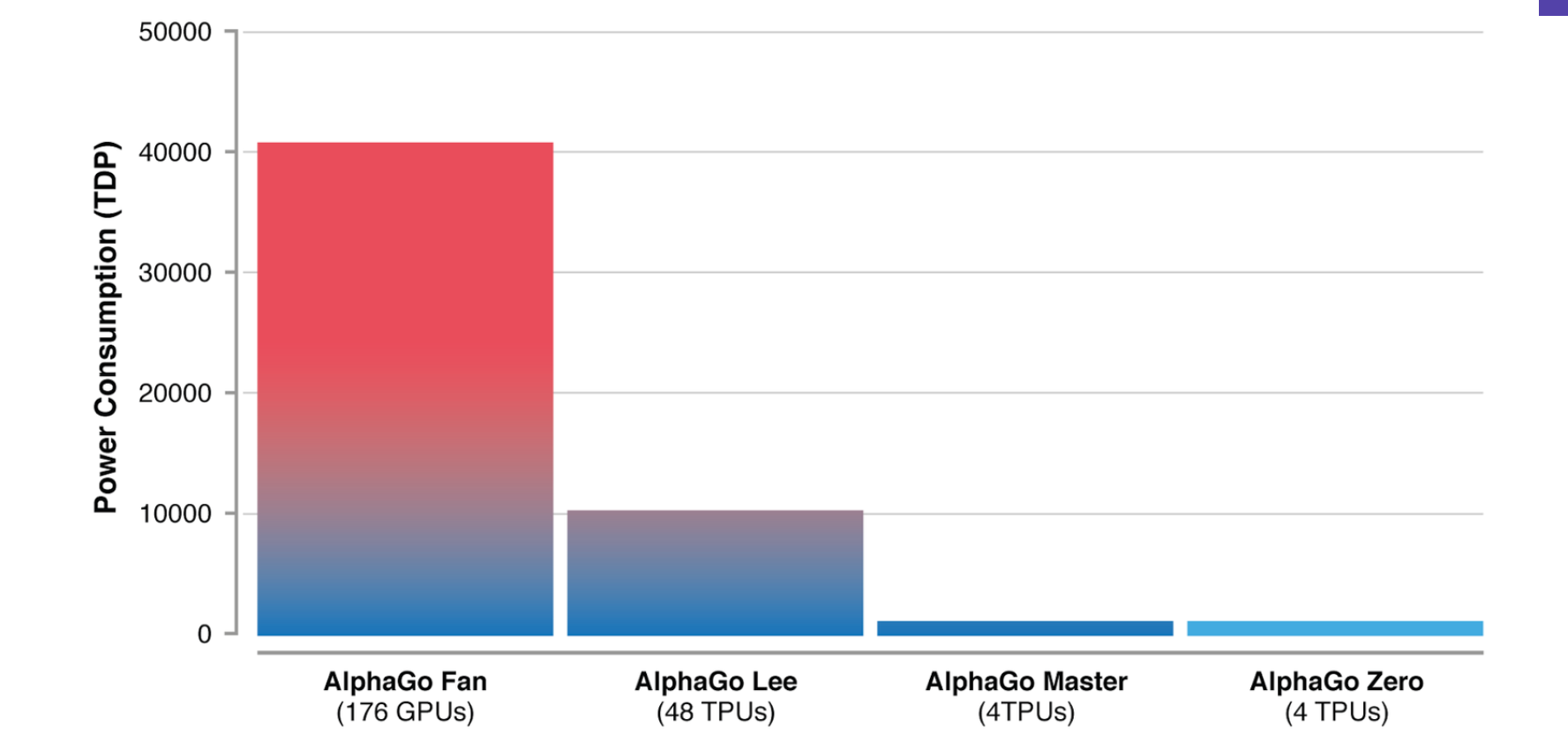
It’s also leaner than the original Go, only needing to know the movements of the black-and-white pieces to start learning on its own, unlike previous versions which were given several “hand-engineered features.” And Zero has just one brain, a combination of the original’s two neutral networks that separately predicted which move to make next and who will be the winner at any given time. Advances in technology make AlphaGo Zero more efficient than its predecessors, needing just four tensor processing units compared to AlphaGo Lee’s 48.
AlphaGo Zero no doubt represents a huge achievement in AI, but it’ll be a while before we see an impact on our everyday lives. Google’s creation is a specialized machine capable of achieving remarkable results, but only in a limited setting with fixed rules. Go may be an extremely complicated game, but it follows a rigid structure not often found in real-world problems.
That said, the introduction of AlphaGo Zero is a milestone moment for artificial intelligence, one even more impressive than those achieved by past versions.

