
Can you tell the difference between this toy turtle and a rifle? Google’s AI couldn’t.

A few months ago, a group of MIT students published a proof-of-concept that showed how, with a couple of tweaks, they were able to trip up Google’s AI while maintaining the natural appearance of a toy turtle to the human eye. It’s one of several projects that reveal the fundamental differences between the way artificial intelligence and humans see the world—and how dangerous these differences can become.
Slowly but surely, AI is taking over tasks that were previously the exclusive domain of humans, from classifying images and analyzing surveillance camera footage to detecting cancer, fighting cybercrime and driving cars, and much more. Yet, despite their superhuman speed and accuracy, AI algorithms can fail spectacularly, such as mistaking turtles for rifles or dunes for nudes.
While these errors often yield comic results, they can also become dangerous given how prominent AI algorithms are becoming in many of the critical things we do every day. And if the scientists and engineers creating them don’t do something about these weaknesses, malicious actors can weaponize them into adversarial attacks to do real damage, both in the virtual and physical world.
How do artificial intelligence algorithms work?
Today’s AI applications mostly rely on artificial neural networks and machine-learning algorithms, a software architecture designed to develop functional rules by analyzing a lot of data. For instance, an AI-based image classifier examines millions of pictures labeled by humans and extracts common patterns that define different objects such as cats, cars, humans, and street signs. Afterward, it will be able to distinguish different things it sees in new images and video.
However, deep-learning algorithms have their own mysterious ways for defining the rules and characteristics governing the world. For example, when you reverse Google’s image classifier and tell it to draw how it sees different objects, what you get is, well, weird. For instance, when asked to draw a dumbbell, Google’s AI created the following image, which implies that it thinks the arm is part of the dumbbell.

This shows how AI algorithms’ perception of the world is different from ours. Unfortunately, the inner workings of neural networks often elude even their creators, which is why they’re often called black boxes. What this also means is that these algorithms might behave in unpredictable ways, and we might not be able to figure out why they do so.
READ MORE:
- The best free password managers
- What’s the most secure operating system?
- How to encrypt an iPhone in seconds
What are adversarial attacks?
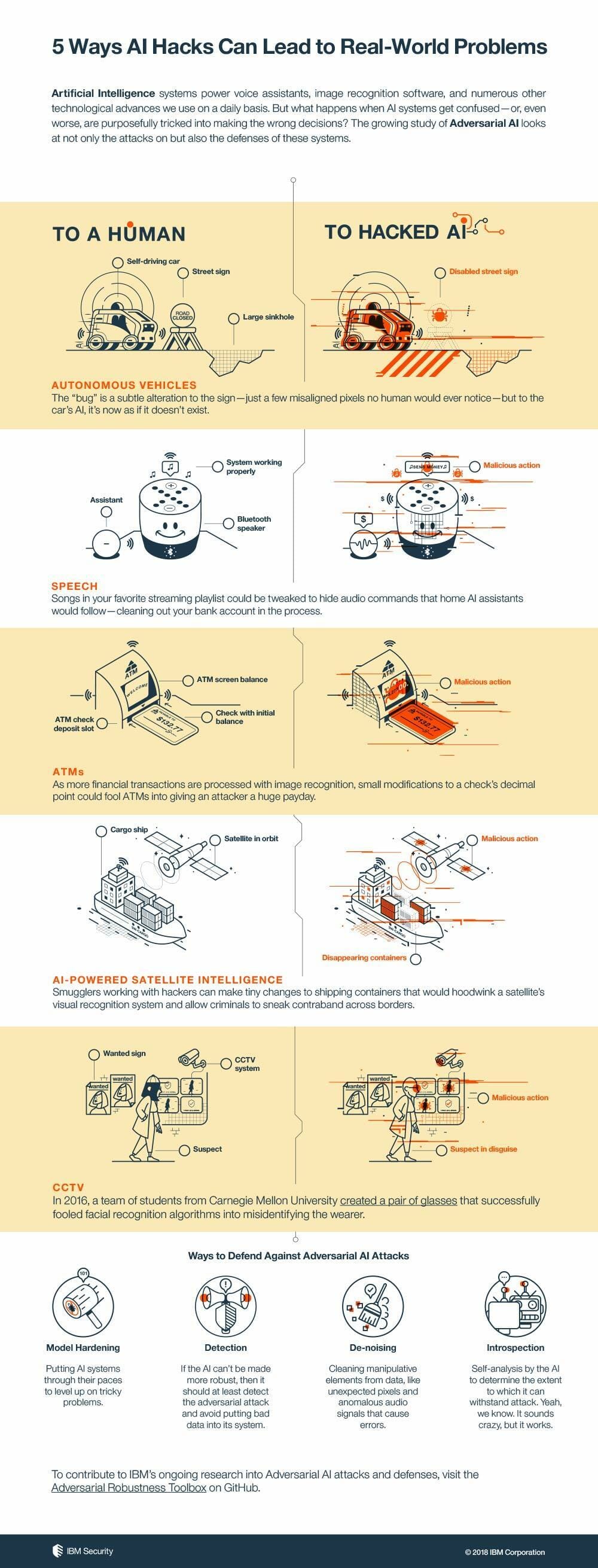
Adversarial attacks involve making modifications to input data to force machine-learning algorithms to behave in ways they’re not supposed to. For instance, in 2016, researchers at Carnegie Mellon University showed that by donning special glasses, they could fool face-recognition algorithms to mistake them for celebrities they certainly did not look like.

This can be extremely significant as the use of face recognition is becoming increasingly common in tagging pictures in social media, protecting sensitive information in smartphones, and providing clearance at important locations.
“Deep neural networks [DNNs] overachieve at tasks that can be performed by humans, giving the impression that they have a higher understanding than we do,” says Sridhar Muppidi, CTO at IBM Security. In practice, however, DNNs aim to simulate human behavior while having a completely different internal decision process composed of mathematical functions.
“Adversarial attacks exploit the sensitivity of models to small changes in the inputs. This is exactly the feature that makes DNNs perform so well in the first place, but at the same time their most vulnerable spot,” Muppidi says. “In contrast, humans are unable to detect, say, small changes affecting a few pixels in an image, making adversarial attacks less recognizable for us.”
Another study by researchers at the University of Michigan, the University of Washington, and the University of California, Berkeley showed that by making small additions to stop signs, they could render them unrecognizable to the machine-vision algorithms that enable self-driving cars to understand their surroundings. The modifications were inconspicuous enough to pass as graffiti or stickers to human observers but could cause an autonomous vehicle to make a dangerous decision.

Muppidi recently published a post that detailed different ways that hackers could exploit weaknesses in AI algorithms to stage adversarial attacks. What’s significant about Muppidi’s work is that it moves beyond the field of computer vision into other areas where AI has made inroads.
For instance, hackers can manipulate songs and audio files so that, when played, they send hidden commands to your AI-powered smart speakers such as Amazon Echo or Google Home. Given that we’re using AI assistants to perform an increasing number of tasks, including placing orders and paying for goods, adversarial attacks against them could be used for very damaging purposes.
“As the practical usage of prediction models becomes more widespread, the risk of attacks increases, and adversaries will come up with new ways of putting AI to the test,” Muppidi says. “That is why it is important to ensure that models are properly secured in all cases, but most crucially in critical applications.”
How bad is it?
While researchers have published many papers showing adversarial attacks against AI systems, for the moment, most of them have remained in proof-of-concept stage and haven’t been used to inflict real damage.
That’s because the attacks often require ample knowledge of the way algorithms work and the data they use. “An adversary needs to have access to the data and have some computation capacities, which will be variable depending on the scale of the attack,” Muppidi says. In most displayed cases, researchers were only able to stage attacks on a case-by-case basis and couldn’t develop a systematic way to compromise neural networks.
Researchers have further found that attacks can’t be staged in a consistent way. For instance, adversarial images will fool image-classifier algorithms when viewed from specific angles and lighting conditions. Likewise, an attack against a smart speaker will have its own requirements and might not work at every distance and when mixed with other ambient noises.
But the attacks nonetheless display the fragility of AI, and Muppidi stresses that the industry must take action before they’re put to practical evil use. “Raising awareness in the tech community that almost all systems need to be designed with security in mind, and that security should be taken into consideration from step one, is going to be as much a challenge as an opportunity in the next years,” he says.
READ MORE:
- What you really need to know about malware
- The best free antivirus tools for Windows and Mac
- How to protect yourself against email spoofing
What’s being done to prevent compromise of AI algorithms?
Tech firms are taking measures to help prevent adversarial attacks against AI systems. In two whitepapers, Google’s researchers introduced ways to train AI algorithms to make them more robust against adversarial attacks. Another method proposed by Google’s researchers is the use of generative adversarial networks (GAN), an AI technique that enables AI systems to create their own high-quality data. Ian Goodfellow, scientist at Google Brain and the inventor of GAN, recently told MIT Technology Review that the method can help create machine-learning algorithms that have baked-in defenses against adversarial attacks.
IBM has also compiled an Adversarial Robustness Toolbox, a set of programming tools that help harden AI algorithms against adversarial attacks. The kit includes the implementation of the most promising attacks, defenses, and robustness metrics currently available.
While attacks are still theoretical, it’s only a matter of time before AI adversarial attacks move from the research labs and into the mainstream. In previous cycles of technological developments, security and defense were patched-on instead of being built into systems. Scientists want to avoid repeating the same mistake with AI and machine learning.
“I want [machine learning] to be as secure as possible before we rely on it too much,” Goodfellow said in his interview with Tech Review.
